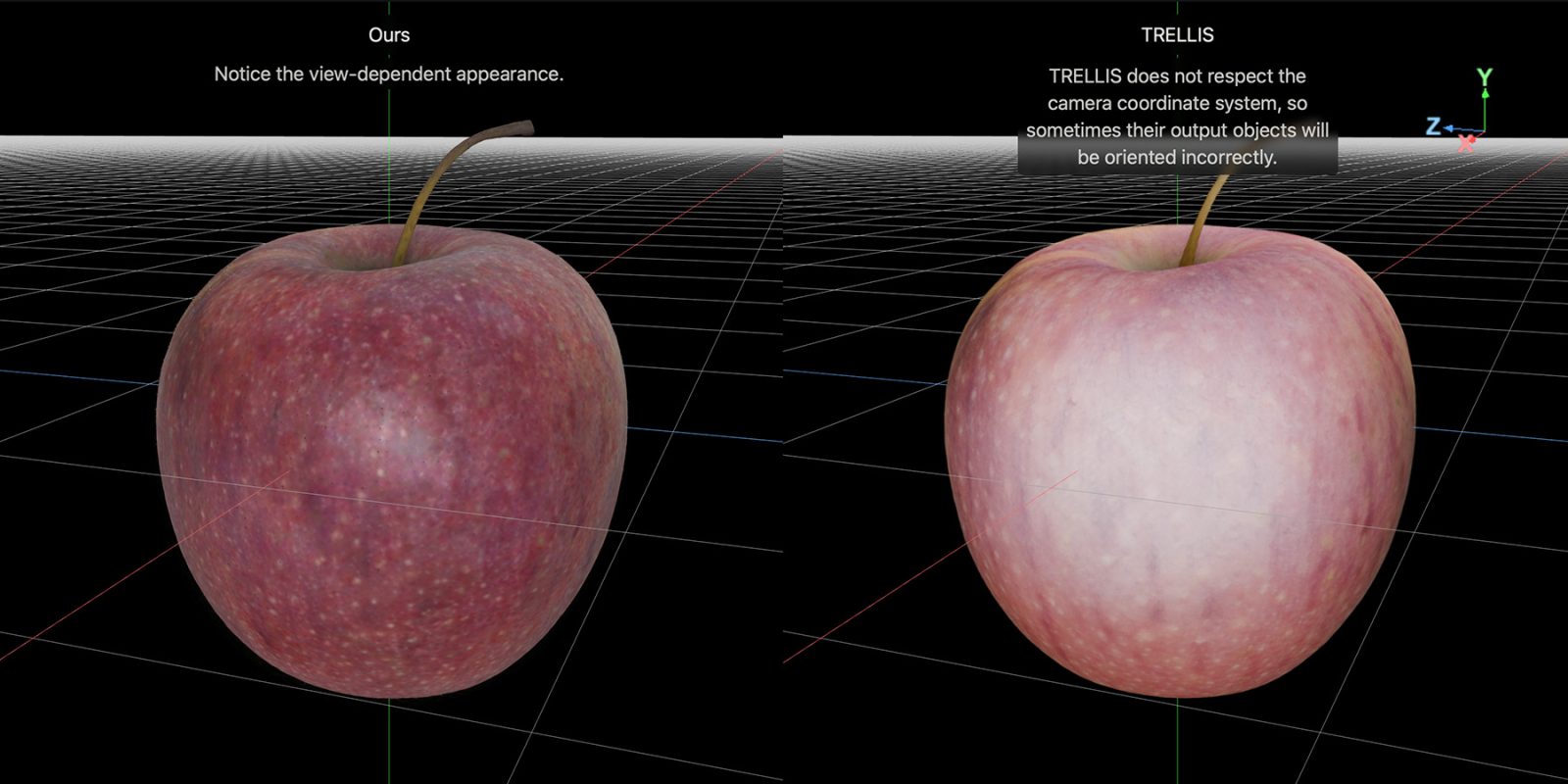
Apple researchers have created an AI model that reconstructs a 3D object from a single image, while keeping reflections, highlights, and other effects consistent across different viewing angles. Here are the details.
A bit of context
While the concept of latent space in machine learning is not exactly new, it has become more popular than ever in recent years, with the explosion of AI models based on the transformer architecture and, more recently, world models.
In a nutshell (and running the risk of being slightly imprecise to explain the bigger picture), “latent space,” or “embedding space,” are terms that describe what happens when you:
- Boil down information to numerical representations of their concepts;
- Organize these numbers in a multi-dimensional space, making it possible to calculate the distances between them for each different dimension.
If that still sounds too abstract, one classic example is to get the mathematical representation of the token “king”, subtract the mathematical representation of the token “man”, add the mathematical representation of the token “woman”, and you will end up in the general multi-dimensional region of the token “queen”.
In practical terms, storing information as mathematical representations in latent space makes it faster and less computationally expensive to measure distances between them and estimate the probability of what should be generated.
Here’s a short video that explains latent space using a different analogy:
Although the examples above focus on storing text in latent space, the same idea can be applied to many other types of data. Which brings us to Apple’s study.
LiTo: Surface Light Field Tokenization
In Apple’s new study, titled LiTo: Surface Light Field Tokenization, the researchers “propose a 3D latent representation that jointly models object geometry and view-dependent appearance.”
In other words, they created a way to represent, in latent space, not only how to reconstruct a three-dimensional object, but also how light interacting with it should appear from different angles.
As they explain it:
Most prior works focus on either reconstructing 3D geometry or predicting view-independent diffuse appearance, and thus struggle to capture realistic view-dependent effects. Our approach leverages that RGB-depth images provide samples of a surface light field. By encoding random subsamples of this surface light field into a compact set of latent vectors, our model learns to represent both geometry and appearance within a unified 3D latent space. This representation reproduces view-dependent effects such as specular highlights and Fresnel reflections under complex lighting.
What’s more, the researchers managed to train the model so it can do all of that from a single image, rather than the more common methods that require images from different angles to enable 3D reconstruction.
While the entire method is highly technical and is explained in detail in the study, the core idea is actually relatively simple, once you understand how latent space works:
- First, an encoder compresses the information about the object into a compact representation in latent space. So, instead of storing every visible detail, it learns a condensed mathematical description of the object’s shape and how light interacts with its surface.
- Then, a decoder does the reverse. It reconstructs the full 3D object from that compact representation, generating both the geometry and the representation of how lighting effects, such as reflections and highlights, should appear from different viewing angles.
Training LiTo
To train the model, the researchers selected thousands of objects rendered from 150 different viewing angles, and 3 lighting conditions.
Then, instead of feeding all of that information directly into the model, the system randomly selected small subsets of these samples and compressed them into a latent representation.
Next, the decoder was trained to reconstruct the full object and its appearance under different angles and light conditions, from just that subset of the data.
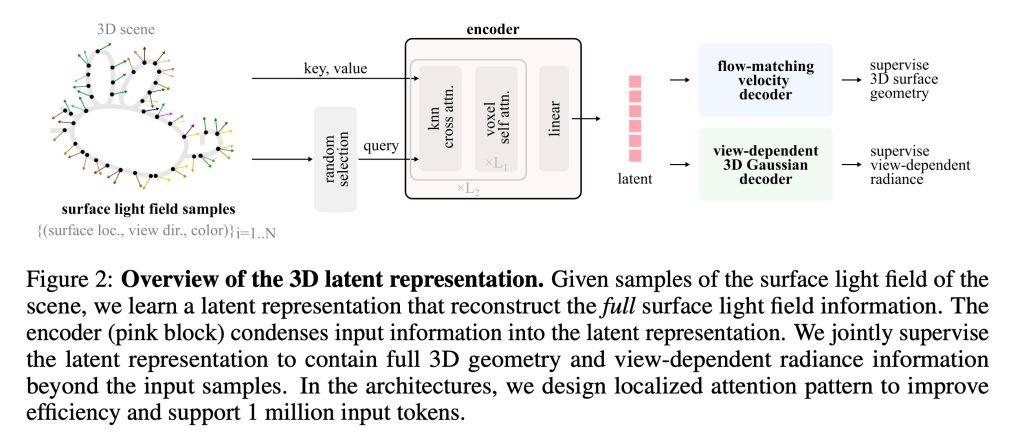
Over the course of training, the system learned a latent representation that captured both the object’s geometry, and how its appearance changes depending on the viewing direction.
Once that was done, they trained yet another model that takes a single image of an object and predicts the latent representation that corresponds to it. Next, the decoder reconstructs the full 3D object, including how its appearance changes as the viewing angle varies.
Here are a few reconstruction comparisons between LiTo and a model called TRELLIS, as Apple published on the project page:
Be sure to check out the project page, where you can also load side-by-side interactive comparisons between LiTo and TRELLIS, as seen in the featured image for this post.
And for the full study, follow this link.
Worth checking out on Amazon
- David Pogue – ’Apple: The First 50 Years’
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2nd Generation) – 4 Pack
- Apple Watch Series 11
- Wireless CarPlay adapter
FTC: We use income earning auto affiliate links. More.

Comments