
The Apple Research team has published a pretty interesting study that investigated whether AI models can estimate heart rate from stethoscope recordings, even though they weren’t specifically trained with that purpose in mind. The short answer is: yes. And this is great news. Here’s why.
In a nutshell, the team took six popular foundation models trained on audio or speech, and tested how well their internal audio representations could be used to estimate heart rate from heart sound recordings, or phonocardiograms.
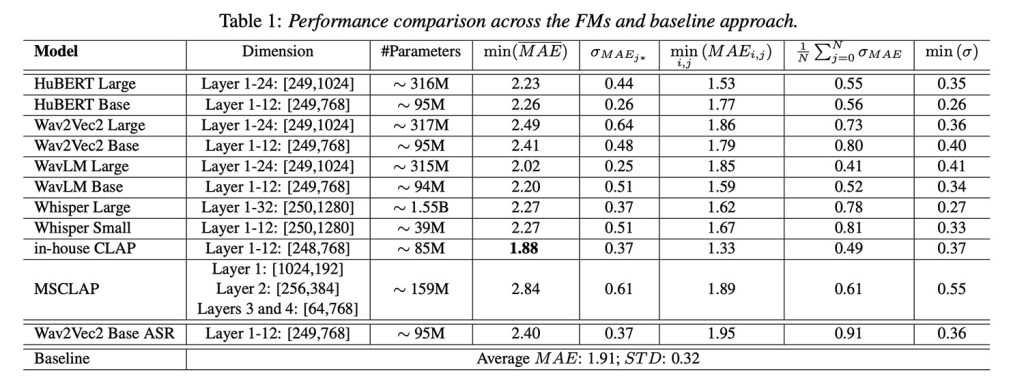
The thing is: even though these models weren’t designed for health data, the results were surprisingly solid. Most models performed just as well as older methods that rely on handcrafted audio features, which are manually engineered ways to represent sound and have long been used in traditional machine learning models.
But the most interesting part? Apple’s own in-house model, a version of CLAP (Contrastive Language-Audio Pretraining) trained internally on 3 million audio samples, actually outperformed the baseline and delivered the best overall performance across various model comparisons.
How did the test work?
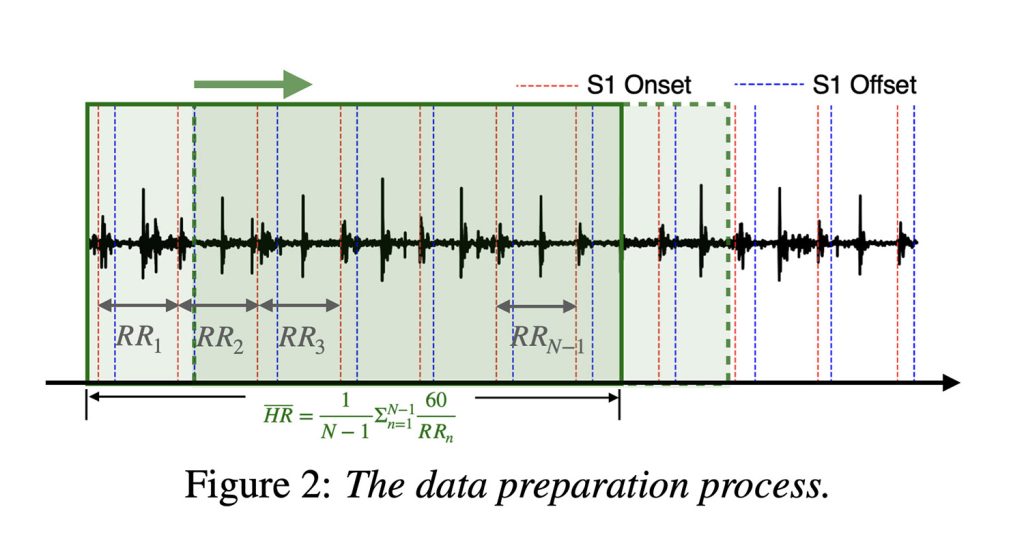
The models were evaluated using a publicly available dataset of over 20 hours of real hospital heart sounds, annotated by experts (which is key for good AI research and performance).
To train the models, Apple broke the recordings into short 5-second clips, moving forward one second at a time. That added up to around 23,000 heart sound snippets, to which Apple then trained a neural network to classify the heart rate into beats per minute values.
Interestingly, some findings went against typical AI assumptions: bigger models didn’t always perform better. Getting a bit more technical, deeper layers within these models often encoded less useful cardiorespiratory information, likely because they were optimized for language. Shallow or mid-layer representations tended to work best.
This is one of the key insights of the study. Because now Apple knows where to look inside these models, and which layers to use, to extract the most relevant health signals if (better yet, when) it decides to bring this sort of analysis to its devices.
Key takeaways
One of the key takeaways of the study is that combining old-school signal processing with next-gen AI leads to more reliable heart rate estimates. This means that in cases where one approach struggled, the other often filled in the gaps. Basically, these two methods pick up on different parts of the signal.
Looking ahead, the researchers say they plan to keep refining the models for health applications, build lighter versions that could run on low-power devices, and explore other body-related sounds that might be worth listening to. Or, in their own words:
“In the future, we plan to: (i) explore combining acoustic features with FM representations, using feature concatenation before the downstream model or through late fusion methods within the model, for improved performance and investigate if such methods are able to capture complementary information and be more robust to individual variabilities;(ii) investigate fine-tuning the FMs to the target domains to reduce the domain mismatch and hence explore if such adaptation translates to improved performance, better mitigate the challenges in HR estimation, and capture complex pathological characteristics; (iii) assess their ap plicability to other downstream tasks and physiological pa rameters, including pathological conditions; (iv) augment and adapt more data that’s clinically significant; (v) compare them with other bioacoustic foundation models, such as HeAR [30]; and (vi) explore model simplification strategies, such as pruning, distillation, and lightweight encoder design, to enable deployable solutions with lower computational cost while maintaining performance.”
The study obviously doesn’t make any clinical claims or product promises. Still, the potential is obvious when it comes to how Apple could embed these models in iPhones, Apple Watches, and especially the AirPods, which rely on in-ear mics for Active Noise Cancellation. If you’ve ever heard your own heartbeat inside your ears while wearing AirPods, you know what I’m talking about.
You can read the full paper on arXiv.
FTC: We use income earning auto affiliate links. More.

Comments